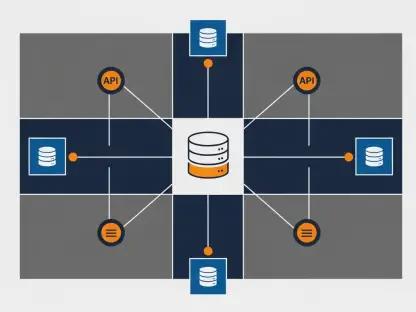
The strategic success of a modern autonomous intelligence system depends far less on the raw complexity of its underlying large language model than on the accessibility, governance, and integrity of the institutional knowledge it consumes daily. As organizations move beyond experimental chatbots toward sophisticated AI agents capable of executing complex workflows, the limitations of traditional data management have become painfully apparent. These agents require more than just a window into a database; they need a comprehensive nervous system that connects disparate information sources into a coherent whole. This architectural shift is defined by the emergence of the data fabric, a unified layer that transforms fragmented data into a strategic asset for autonomous reasoning.
Without a robust data fabric, the most advanced artificial intelligence remains tethered to the quality of its immediate environment, often leading to performance bottlenecks and unreliable outputs. The data fabric serves as a connective tissue, weaving together data warehouses, cloud storage, and localized applications into a single, governed interface. By providing this holistic view, the fabric enables agents to synthesize information across departments, ensuring that a customer service agent has the same context as a supply chain optimizer. This integration is no longer a luxury but a fundamental requirement for any enterprise seeking to scale its AI initiatives without drowning in technical debt.
Why Your Enterprise AI Is Only as Smart as Its Messiest Data Silo
The efficacy of an artificial intelligence agent is fundamentally limited by the boundaries of the data it can perceive and process. In many legacy environments, critical information remains trapped within specialized software or outdated storage systems that do not communicate with one another. When an AI agent attempts to perform a task using only a fraction of the available data, it inevitably produces incomplete or biased results. This reliance on isolated data pockets creates a “intelligence ceiling,” where the agent’s ability to reason is restricted by the messiness of its source material rather than the sophistication of its algorithms.
Modern enterprises often discover that their AI investments fail to deliver value because the underlying data infrastructure is too brittle to support real-time inquiries. A data fabric addresses this by abstracting the complexity of these silos, presenting a clean and unified front to the AI layers above. By centralizing the governance of these sources, organizations ensure that their agents are drawing from a “golden source” of truth. This shift from fragmented silos to a coordinated fabric allows the AI to develop a more nuanced understanding of the business, leading to higher accuracy and more reliable decision-making in autonomous workflows.
The Fragmentation Trap: Why Modern Organizations Are Drowning in Data but Starving for Context
The sheer volume of data generated by modern businesses has become a double-edged sword, creating an environment where information is abundant but meaningful context is scarce. While a company might possess petabytes of raw data, much of it lacks the metadata or relational links necessary for an AI agent to understand its significance. This fragmentation trap forces developers to spend an inordinate amount of time building custom connectors for every new AI use case. Consequently, the agents often operate in a vacuum, lacking the historical and cross-functional context required to navigate complex enterprise problems effectively.
Moreover, the absence of a unified data architecture leads to a phenomenon known as “hallucination by omission,” where an AI fills in the gaps of its knowledge with plausible but incorrect information. When an agent cannot see the full picture due to disconnected systems, it makes assumptions that can jeopardize operational safety or customer trust. A data fabric mitigates this risk by providing the “why” behind the data, linking disparate data points through a shared semantic understanding. This contextual enrichment allows agents to move beyond simple pattern matching toward a deeper, more human-like grasp of organizational logic and intent.
Decoding the Architecture: The Five Primary Categories of AI-Enabled Data Fabrics
To understand how a data fabric supports intelligent agents, one must examine the specific functional variations that have emerged in the current technological landscape. The first category focuses on analytics and machine learning optimization, specifically designed to streamline the pipeline for structured data used in model training. These fabrics excel at high-speed processing but often require additional layers to handle the unstructured data that fuels modern generative AI. In contrast, governance-centric fabrics prioritize data quality and compliance, ensuring that every piece of information an agent touches meets rigorous enterprise standards for privacy and accuracy.
The third and fourth categories involve integration platforms and SaaS-extended connectivity, which aim to bridge the gap between internal APIs and external cloud ecosystems. These fabrics transform the way applications interact, allowing AI agents to pull data from a Salesforce instance and a local SQL server simultaneously without manual intervention. The fifth and most advanced category is the AI-focused fabric, which incorporates specialized features like the Model Context Protocol. These systems are built for real-time query capabilities and persistent lineage tracking, providing a transparent record of how an agent accessed and utilized data to reach a specific conclusion.
Bridging the Context Gap: How Semantic Layers Deliver Long-Term Memory to Intelligent Agents
One of the most persistent hurdles in AI development is the lack of “long-term memory” and situational awareness in autonomous agents. A semantic context layer within a data fabric acts as the shared memory of the organization, storing business rules, process models, and organizational hierarchies in a way that AI can easily interpret. By mapping how different data entities relate to one another, the semantic layer allows an agent to understand that a “client ID” in one system is identical to a “subscriber number” in another. This unified vocabulary is essential for maintaining consistency across multi-agent architectures where different bots must collaborate on a single goal.
Furthermore, this layer facilitates a “many-to-many” connectivity model, where multiple AI models can tap into a single, synchronized stream of institutional knowledge. Instead of training a model on a static dataset that quickly becomes obsolete, the data fabric provides a live feed of contextualized information. This ensures that the agent’s reasoning is always based on the most current data available, effectively granting it a persistent memory of the enterprise’s state. Without this semantic bridge, agents would remain trapped in a cycle of short-term processing, unable to learn from historical patterns or adapt to evolving business conditions.
The Shift to High-Performance Intelligence: Transitioning from Brittle ETL to Zero-ETL Integration
The traditional method of moving data, known as Extract, Transform, Load (ETL), has become a significant liability in the era of high-speed AI. ETL processes are notoriously brittle, often breaking when source schemas change and introducing significant latency that hampers real-time AI responsiveness. As agents are increasingly expected to make split-second decisions in dynamic environments, the hours or days required for traditional data replication are no longer acceptable. Organizations are therefore transitioning toward “Zero-ETL” integration, a method that connects data sources directly without the need for constant, manual movement.
Zero-ETL strategies within a data fabric allow AI agents to query information where it resides, reducing infrastructure overhead and minimizing the risk of data drift. This bidirectional flow of information is crucial for modern workflows where an agent must not only read data but also write updates back to business applications. By streamlining the interaction between the AI and its data sources, the fabric enhances the overall performance and agility of the system. This high-performance gateway ensures that the underlying data architecture can keep pace with the rapid processing speeds of modern large language models.
Guarding the Golden Source: Expert Perspectives on Governance, Security, and Trust in AI Workflows
As AI agents gain the autonomy to act on behalf of an organization, the importance of maintaining a “golden source” of trusted data becomes a matter of security and ethics. A data fabric provides a centralized point for enforcing governance policies, allowing administrators to monitor for biased data or pipeline errors before they influence an agent’s behavior. Trust is the primary currency of autonomous systems; if the data feeding an agent is compromised or inaccurate, the resulting actions can lead to significant financial or reputational damage. The fabric serves as a rigorous gatekeeper, ensuring that only validated and compliant data enters the AI workflow.
Security in this new paradigm is being redefined through the lens of identity and entitlement management within the fabric itself. Experts emphasize the danger of “toxic permission combinations,” where an agent might inadvertently gain access to sensitive executive data by combining multiple low-level permissions. A well-designed data fabric prevents these vulnerabilities by centralizing the management of what an agent is allowed to see and do. By embedding security protocols directly into the data layer, organizations can foster a “security by design” culture that protects sensitive assets while still allowing for the free flow of information necessary for AI innovation.
A Practical Blueprint for Scaling: Implementing Multimodal Support and Sustainable FinOps Strategies
Scaling AI initiatives across a global enterprise requires a strategic approach that encompasses both technical capabilities and financial sustainability. The next evolution of the data fabric involves expanding support for multimodal data, including images, video, and complex document formats like blueprints or medical records. By governing these diverse formats with the same rigor as structured text, the fabric allows agents to operate in more specialized fields such as industrial design or healthcare. This expansion is critical for building agents that can “see” and “hear” the world as humans do, further closing the gap between artificial and natural intelligence.
The implementation of a data fabric also allowed organizations to manage the spiraling costs of data consumption through integrated FinOps strategies. By tracking the financial impact of every data query and model interaction, businesses were able to optimize their infrastructure for maximum efficiency. This transition toward a unified data architecture proved to be the turning point for many enterprises, providing the stability and transparency needed for long-term growth. Leaders realized that the shift toward a data fabric not only mitigated the risks of technical drift but also established a foundation for more trustworthy and autonomous intelligence. The strategic integration of semantic layers eventually enabled agents to resolve complex queries that were previously impossible, setting a new standard for corporate intelligence. Ultimately, the framework provided a clear path forward, transforming raw information into a resilient and actionable strategic asset.